* The script to reproduce the results of this tutorial in Julia is located here.
We continue working with OLS, using the model and data generating process presented in the previous post. Recall that,

or, equivalently,

which is a more convenient expression because the distribution does not depend on 
![\rho \equiv [\beta, \sigma^2]](https://s0.wp.com/latex.php?latex=%5Crho+%5Cequiv+%5B%5Cbeta%2C+%5Csigma%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)


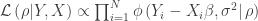
where 

Computing the Log-Likelihood of OLS
First, we define the log-likelihood in Julia as follows (we are using the data X and Y generated in the previous post):
using Distributions function loglike(rho) beta = rho[1:4] sigma2 = exp(rho[5]) residual = Y-X*beta dist = Normal(0, sqrt(sigma2)) contributions = logpdf(dist,residual) loglikelihood = sum(contributions) return -loglikelihood end
This code first collects 


Tip: Always remember to use the negative of the likelihood (or log-likelihood) that you wish to maximize, because the optimize command is a minimizer by default. Since the
The only confusing part of this function is that sigma2 is read from rho as an exponential. This is strictly a unit conversion — it means that ![\rho \equiv [\beta, \log\left(\sigma^2\right)]](https://s0.wp.com/latex.php?latex=%5Crho+%5Cequiv+%5B%5Cbeta%2C+%5Clog%5Cleft%28%5Csigma%5E2%5Cright%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Tip: Always restrict variances so that the optimizer cannot try negative values. We have used log-units to achieve this goal.
Maximizing the Likelihood of OLS
Now, we are ready to find the MLE,
using Optim params0 = [.1,.2,.3,.4,.5] optimum = optimize(loglike,params0,method=:cg) MLE = optimum.minimum MLE[5] = exp(MLE[5]) println(MLE)
This says to optimize the function loglike, starting from the point params0, which is chosen somewhat arbitrarily. Numerical search algorithms have to start somewhere, and params0 serves as an initial guess of the optimum. Of course, the best possible guess is trueParams, because the optimizer would have to do much less work, but in practice, we do not know the true parameters so the optimizer will have to do the work. Notice that, at the end, we have to exponentiate the sigma2 parameter because the optimizer will return it in log-units due to our exponentiation above.
Results
Using the same random seed as before, the algorithm returns the estimates,
julia> MLE
5-element Array{Float64,1}:
0.112163
0.476432
-0.290571
0.010831
1.01085
which are very close to trueParams and the true variance of 
julia> MLE
5-element Array{Float64,1}:
0.112161
0.476435
-0.290572
0.0108343
1.01085
In future posts, we will see cases where the choice of optimizer makes a major difference in the quality of the numerical MLE as well as the speed of computation, but for this simple example, the choice of optimizer does not much matter.
Bradley J. Setzler
 ,
, is the
is the  dependent variable,
dependent variable,  matrix of independent variables,
matrix of independent variables,  is the
is the 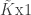 vector of parameters that we wish to estimate, and
vector of parameters that we wish to estimate, and  error satisfying
error satisfying  . Because we assume that the first column of
. Because we assume that the first column of  . The least squares estimator is,
. The least squares estimator is, .
.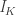 , the identity matrix of size
, the identity matrix of size 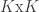 . We only told MvNormal the covariance matrix, leaving the mean blank, which Julia assumes means that we would like a zero mean. The distribution of
. We only told MvNormal the covariance matrix, leaving the mean blank, which Julia assumes means that we would like a zero mean. The distribution of 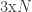 matrix, when we need it to be
matrix, when we need it to be  . Misaligned dimensions are one of the most common and frustrating errors to make in writing a program.
. Misaligned dimensions are one of the most common and frustrating errors to make in writing a program.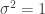 .
.