* The script to reproduce the results of this tutorial in Julia is located here.
To finish yesterday’s tutorial on hypothesis testing with non-parametric p-values in Julia, I show how to perform the bootstrap stepdown correction to p-values for multiple testing, which many economists find intimidating (including me) but is actually not so difficult.
First, I will show the simple case of Holm’s (1979) stepdown procedure. Then, I will build on the bootstrap example to apply one of the most exciting advances in econometric theory from the past decade, the bootstrap step-down procedure, developed by Romano and Wolf (2004) and extended by Chicago professor Azeem Shaikh. These methods allow one to bound the family-wise error rate, which is the probability of making at least one false discovery (i.e., rejecting a null hypothesis when the null hypothesis was true).
Motivation
The standard example to motivate this discussion is to suppose you compute p-values for, say, 10 parameters with independent estimators. If all 10 have p-value equal to 0.05 corresponding to the null hypothesis of each, then we reject the null hypothesis for any one of them with 95% confidence. However, the probability that all of them reject the null hypothesis is 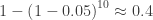
The Romano-Wolf-Shaikh approach is to account for the dependence among the estimators, and penalize estimators more as they become more independent. Here’s how I motivate their approach: First, consider the extreme case of two estimators that are identical. Then, if we reject the null hypothesis for the first, there is no reason to penalize the second; it would be very strange to reject the null hypothesis for the first but not the second when they are identical. Second, suppose they are almost perfectly dependent. Then, rejecting the null for one strongly suggests that we should also reject the null for the second, so we do not want to penalize one very strongly for the rejection of the other. But as they become increasingly independent, the rejection of one provides less and less affirmative information about the other, and we approach the case of perfect independence shown above, which receives the greatest penalty. The specifics of the procedure are below.
Holm’s Correction to the p-values
Suppose you have a vector of p-values, 


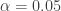
- If the smallest element of
, reject no null hypotheses and exit (do not continue to step 2). Else, reject the null hypothesis corresponding to the smallest element of
- If the second-smallest element of
, reject no remaining null hypotheses and exit (do not continue to step 3). Else, reject the null hypothesis corresponding to the second-smallest element of
- If the third-smallest element of
, reject no remaining null hypotheses and exit (do not continue to step 4). Else, reject the null hypothesis corresponding to the third-smallest element of
- And so on.
We could program this directly as a loop-based function that takes 
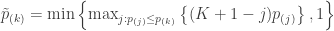
where 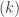
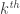
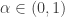

The following code computes these p-values. Julia (apparently) lacks a command that would tell me the index of the rank of the p-values, so my loop below does this, including the handling of ties (when some of the p-values are the same):
function Holm(p)
K = length(p)
sort_index = -ones(K)
sorted_p = sort(p)
sorted_p_adj = sorted_p.*[K+1-i for i=1:K]
for j=1:K
num_ties = length(sort_index[(p.==sorted_p[j]) & (sort_index.<0)])
sort_index[(p.==sorted_p[j]) & (sort_index.<0)] = j:(j-1+num_ties)
end
sorted_holm_p = [minimum([maximum(sorted_p_adj[1:k]),1]) for k=1:K]
holm_p = [sorted_holm_p[sort_index[k]] for k=1:K]
return holm_p
end
This is straight-forward except for sort_index, which I constructed such that, e.g., if the first element of sort_index is 3, then the first element of pvalues is the third smallest. Unfortunately, it arbitrarily breaks ties in favor of the parameter that appears first in the MLE array, so the second entry of sort_index is 1 and the third entry is 2, even though the two corresponding p-values are equal.
Please email me or leave a comment if you know of a better way to handle ties.
Bootstrap Stepdown p-values
Given our work yesterday, it is relatively easy to replace bootstrap marginal p-values with bootstrap stepdown p-values. We begin with samples, as created yesterday. The following code creates tNullDistribution, which is the same as nullDistribution from yesterday except as t-statistics (i.e., divided by standard error).
function stepdown(MLE,bootSamples)
K = length(MLE)
tMLE = MLE
bootstrapSE = std(bootSamples,1)
tNullDistribution = bootSamples
p = -ones(K)
for i=1:K
tMLE[i] = abs(tMLE[i]/bootstrapSE[i])
tNullDistribution[:,i] = abs((tNullDistribution[:,i]-mean(tNullDistribution[:,i]))/bootstrapSE[i])
p[i] = mean(tMLE[i].<tNullDistribution[:,i])
end
sort_index = -ones(K)
stepdown_p = -ones(K)
sorted_p = sort(p)
for j=1:K
num_ties = length(sort_index[(p.==sorted_p[j]) & (sort_index.<0)])
sort_index[(p.==sorted_p[j]) & (sort_index.<0)] = j:(j-1+num_ties)
end
for k=1:K
current_index = [sort_index.>=k]
stepdown_p[sort_index[k]] = mean(maximum(tNullDistribution[:,sort_index.>=k],2).>tMLE[sort_index[k]])
end
return ["single_pvalues"=>p,"stepdown_pvalues"=>stepdown_p,"Holm_pvalues"=>Holm(p)]
end
The only difference between the single p-values and the stepdown p-values is the use of the maximum t-statistic in the comparison to the null distribution, and the maximum is taken over only the parameter estimates whose p-values have not yet been computed. Notice that I used a dictionary in the return so that I could output single, stepdown, and Holm p-values from the stepdown function.
Results
To test out the above corrected p-values, we return to MLE and samples from yesterday. Suppose we want to perform the two-sided tests simultaneously for the null hypotheses 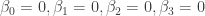
julia> stepdown(MLE[1:4],samples[:,1:4])
Dict{ASCIIString,Any} with 3 entries:
"Holm_pvalues" => {0.766,0.766,0.18,0.036}
"stepdown_pvalues" => [0.486,0.649,0.169,0.034]
"single_pvalues" => [0.486,0.383,0.06,0.009]
We see that the p-value corresponding to the null hypothesis 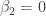
Bradley J. Setzler

There is a package for Julia called PValueAdjust.jl that has a implementation of the Holm method.
Hi Johan,
Thanks for letting me know about this package. How did you decide to handle ties (two p-values being numerically identical)? In theory, ties are a zero-probability event; in practice, I have seen plenty of them.
All the best,
Bradley
I cannot take credit for the package. It is the work of Dirk Schumacher. Looking at the code https://github.com/dirkschumacher/PValueAdjust.jl/blob/master/src/holm.jl it doesn’t seem to take ties into account, which, I suppose, results in ties getting the same value.