* Scripts that reproduce the results of this tutorial in Julia are located here and here.
To review our extended example, we first simulated the OLS DGP, solved for the MLE of OLS, bootstrapped the MLE, and computed various non-parametric p-values.
The only part of our previous work that may have slowed down your computer was forming the 10,000 bootstrap samples (samples). In this post, we will see how to speed up the bootstrapping by using more than one processor to collect the bootstrap samples.
The Estimator that We Wish to Bootstrap
We are interested in the following MLE estimator, adapted from our previous work. First, we import the two needed packages and generate the data:
# Prepare
srand(2)
using Distributions
using Optim
using DataFrames
N=1000
K=3
# Generate variables
genX = MvNormal(eye(K))
X = rand(genX,N)
X = X'
X_noconstant = X
constant = ones(N)
X = [constant X]
genEpsilon = Normal(0, 1)
epsilon = rand(genEpsilon,N)
trueParams = [0.01,0.05,0.05,0.07]
Y = X*trueParams + epsilon
# Export data
data = DataFrame(hcat(Y,X))
names!(data,[:Y,:one,:X1,:X2,:X3])
writetable("data.csv",data)
Next, we define the likelihood of OLS:
function loglike(rho,y,x)
beta = rho[1:4]
sigma2 = exp(rho[5])+eps(Float64)
residual = y-x*beta
dist = Normal(0, sqrt(sigma2))
contributions = logpdf(dist,residual)
loglikelihood = sum(contributions)
return -loglikelihood
end
Finally, we define the bootstrap function, which includes within it a wrapper for the likelihood:
function bootstrapSamples(B)
println("hi")
samples = zeros(B,5)
for b=1:B
theIndex = sample(1:N,N)
x = X[theIndex,:]
y = Y[theIndex,:]
function wrapLoglike(rho)
return loglike(rho,y,x)
end
samples[b,:] = optimize(wrapLoglike,params0,method=:cg).minimum
end
samples[:,5] = exp(samples[:,5])
println("bye")
return samples
end
The reason for the cute println statements will become apparent later. Save all of this in a file called “bootstrapFunction.jl”. Finally, we import the data created above:
data = readtable("data.csv")
N = size(data,1)
Y = array(data[:Y])
X = array(data[[:one,:X1,:X2,:X3]])
Parallel Bootstrapping
We now have the function, bootstrapSamples, saved in the file “bootstrapFunction.jl”, that we wish to run in parallel. The idea is that, instead of running the MLE 

Instead, we separate our work into two files, the first one you have already created. Create a second file in the same location on your computer as “bootstrapFunction.jl”. In the second file, write the following commands:
addprocs(4)
require("tutorial_5_bootstrapFunction.jl")
B=10000
b=2500
samples_pmap = pmap(bootstrapSamples,[b,b,b,b])
samples = vcat(samples_pmap[1],samples_pmap[2],samples_pmap[3],samples_pmap[4])
The command addprocs(4) means to add four processors into your Julia session. The command require is the key to getting this right: it ensures that all of the functions and parameters contained in “bootstrapFunction.jl” are available to each processor. pmap is the function that actually applies bootstrapSamples to each value in the list [b,b,b,b]. I set the list next to it to be [b,b,b,b], where b=2500, so that bootstrapEstimates would collect 2,500 bootstrap samples on each processor. The resulting matrices from all four processors are stored in the length-4 vector called samples_pmap. Finally, we vertically stack (vcat) the four matrices into one matrix, samples, which is exactly the matrix of bootstrap samples we have seen previously.
Tip: For parallel processing in Julia, separate your code into two files, one file containing the functions and parameters that need to be run in parallel, and the other file managing the processing and collecting results. Use the require command in the managing file to import the functions and parameters to all processors.
Results
Once you have run the outer file, you can do speed tests to compare the two ways of getting 10,000 bootstrap samples. We use the @elapsed command to time each code. Here are the results:
@elapsed pmap(bootstrapSamples,[b,b,b,b]) From worker 2: hi From worker 3: hi From worker 4: hi From worker 5: hi From worker 2: bye From worker 5: bye From worker 4: bye From worker 3: bye 66.528345161
Each of the processors tells us “hi” and “bye” when it begins and finishes its job, respectively. The total time was a bit more than a minute (66.5 seconds). By comparison, the following code will compute 10,000 bootstrap samples on only one processor, as in our previous work:
@elapsed bootstrapSamples(10000) hi bye 145.265103729
So, in the absence of parallel processing, the same result would require just over 145 seconds, or almost two and a half minutes. Thus, parallel processing on a four-core personal computer allowed us to reduce the time required to bootstrap our estimator by a factor of around 2.2. As a general rule, parallel processing of the bootstrap estimator saves you more time when the function being bootstrapped is more complicated.
Bradley J. Setzler
 are statistically different from zero and if the estimate of
are statistically different from zero and if the estimate of  is different from one for the OLS parameters defined
is different from one for the OLS parameters defined  individuals as if it were a population from which we randomly draw
individuals as if it were a population from which we randomly draw  , holding x and y fixed, but we also want to be able to adjust x and y to suit our purposes. The wrapper function allows the user to modify x and y, but tells the optimizer not to bother them.
, holding x and y fixed, but we also want to be able to adjust x and y to suit our purposes. The wrapper function allows the user to modify x and y, but tells the optimizer not to bother them. by subtracting the mean from each distribution (thus imposing a zero mean) and then adding 1 to the distribution of
by subtracting the mean from each distribution (thus imposing a zero mean) and then adding 1 to the distribution of  against the alternative that
against the alternative that 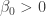 :
: :
: , but find insufficient evidence to reject the null hypotheses that
, but find insufficient evidence to reject the null hypotheses that 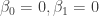 and
and 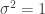 .
.