* The script to reproduce the results of this tutorial in Julia is located here.
Suppose that we wish to test to see if the the parameter estimates of 

We decide to bootstrap by resampling cases in order to estimate the standard errors. This means that we treat the sample of 

To perform bootstrapping, we rely on Julia’s built-in sample function.
Wrapper Functions and the Likelihood of Interest
Now that we have a bootstrap index, we define the log-likelihood as a function of x and y, which are any subsets of X and Y, respectively.
function loglike(rho,y,x) beta = rho[1:4] sigma2 = exp(rho[5]) residual = y-*(x,beta) dist = Normal(0, sqrt(sigma2)) contributions = logpdf(dist,residual) loglikelihood = sum(contributions) return -loglikelihood end
Then, if we wish to evaluate loglike across various subsets of x and y, we use what is called a wrapper, which simply creates a copy of loglike that has already set the values of x and y. For example, the following function will evaluate loglike when x=X and y=Y:
function wrapLoglike(rho) return loglike(rho,Y,X) end
We do this because we want the optimizer to find the optimal 
Tip: Use wrapper functions to manage arguments of your objective function that are not supposed to be accessed by the optimizer. Give the optimizer functions with only one argument — the parameters over which it is supposed to optimize your objective function.
Bootstrapping the OLS MLE
Now, we will use a random index, which is drawn for each b using the sample function, to take a random sample of individuals from the data, feed them into the function using a wrapper, then have the optimizer maximize the wrapper across the parameters. We repeat this process in a loop, so that we obtain the MLE for each subset. The following loop stores the MLE in each row of the matrix samples using 1,000 bootstrap samples of size one-half (M) of the available sample:
B=1000
samples = zeros(B,5)
for b=1:B
theIndex = sample(1:N,N)
x = X[theIndex,:]
y = Y[theIndex,:]
function wrapLoglike(rho)
return loglike(rho,y,x)
end
samples[b,:] = optimize(wrapLoglike,params0,method=:cg).minimum
end
samples[:,5] = exp(samples[:,5])
The resulting matrix contains 1,000 samples of the MLE. As always, we must remember to exponentiate the variance estimates, because they were stored in log-units.
Bootstrapping for Non-parametric p-values
Estimates of the standard errors of the MLE estimates can be obtained by computing the standard deviation of each column,
bootstrapSE = std(samples,1)
where the number 1 indicates that the standard deviation is taken over columns (instead of rows).
Standard errors like these can be used directly for hypothesis testing under parametric assumptions. For example, if we assume an MLE is normally distributed, then we reject the null hypothesis that the parameter is equal to some point if the parameter estimate differs from the point by at least 1.96 standard errors (using that the sample is large). However, we can make fewer assumptions using non-parametric p-values. The following code creates the distribution implied by the null hypothesis that 
nullDistribution = samples pvalues = ones(5) for i=1:5 nullDistribution[:,i] = nullDistribution[:,i]-mean(nullDistribution[:,i]) end nullDistribution[:,5] = 1 + nullDistribution[:,5]
The non-parametric p-value (for two-sided hypothesis testing) is the fraction of times that the absolute value of the MLE is greater than the absolute value of the null distribution.
pvalues = [mean(abs(MLE[i]).<abs(nullDistribution[:,i])) for i=1:5]
If we are interested in one-sided hypothesis testing, the following code would test the null hypothesis 
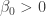
pvalues = [mean(MLE[i].<nullDistribution[:,i]) for i=1:5]
Conversely, the following code would test the null hypothesis 
pvalues = [mean(MLE[i].>nullDistribution[:,i]) for i=1:5]
Thus, two-sided testing uses the absolute value (abs), and one-sided testing only requires that we choose the right comparison operator (.> or .<).
Results
Let the true parameters be,
julia> trueParams = [0.01,0.05,0.05,0.07]
The resulting bootstrap standard errors are,
julia> bootstrapSE = std(samples,1)
1x5 Array{Float64,2}:
0.0308347 0.0311432 0.0313685 0.0305757 0.0208229
and the non-parametric two-sided p-value estimates are,
julia> pvalues = [mean(abs(MLE[i]).<abs(nullDistribution[:,i])) for i=1:5]
5-element Array{Any,1}:
0.486
0.383
0.06
0.009
0.289
Thus, we reject the null hypotheses for the third and fourth parameters only and conclude that 
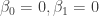
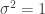
Bradley J. Setzler
 ,
, ,
, , conditional on
, conditional on ![\rho \equiv [\beta, \sigma^2]](https://s0.wp.com/latex.php?latex=%5Crho+%5Cequiv+%5B%5Cbeta%2C+%5Csigma%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002) . We will now see how to obtain the MLE estimate
. We will now see how to obtain the MLE estimate  of
of 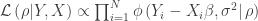 ;
; is the normal probability distribution function (PDF).
is the normal probability distribution function (PDF).  of this expression, and we will show how to find it using a numerical search algorithm in Julia.
of this expression, and we will show how to find it using a numerical search algorithm in Julia. (beta) and
(beta) and  (residuals), returning the negative of the sum of the individual contributions to the log-likelihood (contributions).
(residuals), returning the negative of the sum of the individual contributions to the log-likelihood (contributions).![\rho \equiv [\beta, \log\left(\sigma^2\right)]](https://s0.wp.com/latex.php?latex=%5Crho+%5Cequiv+%5B%5Cbeta%2C+%5Clog%5Cleft%28%5Csigma%5E2%5Cright%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This is a common approach in numerical optimization to solve a practical problem: the numerical optimizer tries out many possible values for
. This is a common approach in numerical optimization to solve a practical problem: the numerical optimizer tries out many possible values for  units, we make it perfectly acceptable for the optimizer to try out a negative value of the parameter, because a parameter that is negative in log-units is non-negative in level-units.
units, we make it perfectly acceptable for the optimizer to try out a negative value of the parameter, because a parameter that is negative in log-units is non-negative in level-units. , 1. The Optim package has various optimizers from which to choose; we were using the Newton Conjugate-Gradient (cg) algorithm above. If we replace this with the Nelder-Mead algorithm (nelder_mead), we obtain the almost-identical estimates,
, 1. The Optim package has various optimizers from which to choose; we were using the Newton Conjugate-Gradient (cg) algorithm above. If we replace this with the Nelder-Mead algorithm (nelder_mead), we obtain the almost-identical estimates, ,
, is the
is the  dependent variable,
dependent variable,  matrix of independent variables,
matrix of independent variables, 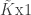 vector of parameters that we wish to estimate, and
vector of parameters that we wish to estimate, and  error satisfying
error satisfying  . Because we assume that the first column of
. Because we assume that the first column of  . The least squares estimator is,
. The least squares estimator is, .
.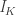 , the identity matrix of size
, the identity matrix of size 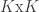 . We only told MvNormal the covariance matrix, leaving the mean blank, which Julia assumes means that we would like a zero mean. The distribution of
. We only told MvNormal the covariance matrix, leaving the mean blank, which Julia assumes means that we would like a zero mean. The distribution of 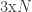 matrix, when we need it to be
matrix, when we need it to be  . Misaligned dimensions are one of the most common and frustrating errors to make in writing a program.
. Misaligned dimensions are one of the most common and frustrating errors to make in writing a program.